Named Entity Recognition#
Inhaltsverzeichnis#
Was ist Named Entity Recognition (NER) ?
Was ist ein NER-Tagger und wie wird er trainiert?
Welche NER-Tagger stehen für Altgriechisch und Latein zur Verfügung?
Welche Anwendungsmöglichkeiten für NER gibt es in der Klassischen Philologie?
Wie arbeitet man mit NER in der literaturwissenschaftlichen Forschung?
Einführung#
Was ist Named Entity Recognition (NER) ?#
Named Entity Recognition and Classification (NER) ist eine Methode des Information Retrieval, d.h. der automatischen Extraktion und Klassifizierung von Informationen aus einem Textkorpus. Unter Named Entities (NE) werden Begriffe verstanden, die über einen eindeutigen Namen (Entität) einer Kategorie (“Klasse”) zugewiesen werden können, z.B. Cicero = Person, Roma = Ort, Galli = Volk, ecclesia = Organisation, consulibus M. Antonio Hybrida et M. Tullio Cicerone = Datum. Besonders herausfordernd ist die automatische (semantische) Disambiguierung von Entitäten, d.h. die eindeutige Zuweisung zur eigentlich gemeinten Entität.
Beispiel: Wie löst ein Algorithmus bei einem Mehrwortausdruck die Entitäten auf?
bei verschiedenen Konstruktionsmöglichkeiten, z.B. vallum Hadriani, P. et Ser. Sullae Ser. Filii,
bei unterschiedlicher Spannweite, z.B. rebus Sancti Vincentii Matiscensis, oder
bei Überlappungen, z.B. Guillelmus de Sancti Stephano de Ponte
Anwendungsfelder für NER sind u.a. Textklassifikation, soziale Netzwerkanalysen, Zeitleisten, Meinungsforschung, Übersetzungen, Geodatenanalysen.
Was ist ein NER-Tagger und wie wird er trainiert?#
Ein NER-Tagger ist ein Algorithmus, der für einen beliebigen Text eine annotierte Textfassung erzeugt, in der sowohl der ursprüngliche Text als auch Annotationen für Personen, Orte usw. enthalten sind (Ehrmann et al. 2021, 5f.). Die Annotationen liegen digital vor und können beispielsweise im Textformat (.txt) oder mit farbigen Markierungen in einer Webdatei (.html) oder Bilddatei (.png) ausgegeben werden.
Bei der Verarbeitung des Textes weist der NER-Tagger jedem Wort eine Kategorie zu (z.B. Person, Ort, oder Keine Entität). Manche Algorithmen ergänzen pro Wort auch noch einen Zahlenwert zwischen 0 und 1. Dieser Wert gibt die Konfidenz des Algorithmus für dieses Wort an, also wie sicher er sich mit dieser Entscheidung ist. Ein höherer Wert deutet hier eher auf ein korrektes Ergebnis hin als ein niedrigerer, ähnlich wie bei Menschen.
Für das Training von NER-Taggern werden verschiedene Verfahren genutzt:
Lexikon- und regelbasierte Methode
Vergleich eines Wörterbuchs mit der Liste der Wörter im ausgewählten Korpus,
transparent und systematisch,
Einschränkungen: Verfügbarkeit und Qualität der Lexika, Komplexität der Entitäten (u.a. Ambiguität, Schreibvarianten etc.)
Merkmal-basierte Methode (Machine Learning)
in gelabelten Daten werden systematisch Muster (Merkmale) erkannt, die auf ungelabelte Daten übertragen werden
transparent und systematisch, auf neue Kontexte übertragbar
Einschränkungen: große Menge an gelabelten Daten erforderlich, komplexe Probleme der Entitätenerkennung (Ambiguitäten, Mehrwortausdrücke) so nicht lösbar
Neuronal-basierte Methode (Deep Learning)
neuronale Netze mit mehreren Verarbeitungsschichten nutzen Wortvektoren, um die semantische und syntaktische Beziehung zwischen verschiedenen Wörtern durch das Lernen von Repräsentationen der gegebenen Daten (Korpus) zu modellieren
intransparent und unsystematisch, liefert aber (mit ausreichend Trainingsdaten) oft die besten Ergebnisse
Einschränkungen: Arbeitsweise opak („Black Box“), Entscheidungsprozesse nicht transparent, unsystematisch
Besonderheiten für Latein und Altgriechisch:
sog. low-resource languages, d.h. eher kleine Korpora (rund 150 Mio. Wörter aus der römisch-griechischen Antike)
kleine Community, eher unterfinanziert und zu wenig Daten affin; Datenarbeit wird nicht als Forschung betrachtet
geringe Ressourcen, v.a. existieren zu wenig qualitativ hochwertig annotierte Datensets für das Training
geringe Anzahl an robusten Sprachmodellen
mangelnde Standards, z.B. bei Annotationsrichtlinien, Dokumentation etc.
dynamische Sprachentwicklung: unterschiedliche Normalisierung, (zu wenig digital erfasste) Spezifika wie Metaphern oder poetische Ausrücke, Homonyme, Mehrwort-Ausdrücke, Bedeutungswandel über Zeit
Welche NER-Tagger sind für die Alten Sprachen verfügbar?#
Latein
Aguilar 2022 trainiert einen NER-Tagger für mittelalterliche Urkunden (https://huggingface.co/magistermilitum/roberta-multilingual-medieval-ner). Gemäß Chastang, Torres Aguilar & Tannier 2021 gibt es für diesen Tagger sogar eine eigene Website, um ihn leichter nutzbar zu machen: https://entities-recognition.irht.cnrs.fr/ .
Altgriechisch
Yousef, Palladino & Jänicke 2023 und Palladino & Yousef 2024 stellen eine Reihe von Deep-Learning-basierten NER-Taggern vor und machen sie öffentlich verfügbar (https://huggingface.co/UGARIT).
Andere Optionen
González-Gallardo et al. 2024 zeigen, wie man große Sprachmodelle (ChatGPT & Co.) für NER bei historischen, u.a. auch antiken, Texten nutzen kann.
Yousef et al. 2023 nutzen Annotationsprojektion, um die leistungsstarken NER-Tagger, die es für moderne Sprachen gibt, mittels der Alignierung von Übersetzungen auch in antiken Kontexten nutzen zu können.
Milanova et al. 2019 stellen einen regelbasierten Ansatz für NER in lateinischen Texten vor.
Anwendungsmöglichkeiten von NER in der Klassischen Philologie: einige Beispiele#
Potentielle Forschungsthemen mit NER-Bezug
Digital (Scholarly) Editions
Prosopografien, Personen- und Ortsregister/-indizes
Integration externer Ressourcen wie Brills Der Neue Pauly Online durch Named Entity Linking und Linked Open Data
bessere Durchsuchbarkeit (z.B. facettenbasierte Suche) durch NER in Verbindung mit der Auflösung von Koreferenzen (Coreference Resolution) und Disambiguierung
Quellenforschung und Alte Geschichte
Architekturgeschichte, z.B. für berühmte Bauwerke wie das Amphitheatrum Flavium, das Pantheon oder den Parthenon
Quellenkritik, W-Fragen
Religionsgeschichte, z.B. Ausbreitung des Christentums
Computational Literary Studies
Bezeichnung und Funktion für plot-interne vs. plot-externe Figuren
Häufung von Eigennamen als kulturspezifisches Merkmal von Literatur
Beschreibung des sozialen Kapitals von Frauen in der antiken Tragödie
Analyse von Stereotypen in der Historiographie
Existierende Beispiele aus der analogen Forschung, die von NER-Analysen potentiell hätten bereichert werden können:
The Prosopographia Imperii Romani (PIR) and New Trends and Projects in Roman Prosopography (2007)
Prosopography meets the digital: PBW and PASE (2007)
A small Greek world: networks in the Ancient Mediterranean (2011)
Women’s social networks and female friendship in the ancient Greek city (2011)
Religious networks in the Roman Empire: The spread of new ideas (2013)
Proxeny and polis: institutional networks in the ancient Greek world (2015)
Nominal Intelligence: Conspiracy, Prosopography, and the Secret of Horace, Odes 2.10 (2016)
Existierende Beispiele aus der digitalen Forschung, die NER eingesetzt haben:
Developing onomastic gazetteers and prosopographies for the ancient world through named entity recognition and graph visualization: Some examples from trismegistos people (2014)
Named entity recognition applied on a data base of Medieval Latin charters. The case of chartae burgundiae (2016)
A comparison of sequential and combined approaches for named entity recognition in a corpus of handwritten medieval charters (2020)
Named Entity Recognition for a Text-Based Catalog of Ancient Greek Authors and Works (2023)
Anwendungsbeispiel: Ps.-Sallust In Ciceronem#
Hintergrund:
Pseudo-Sallust: ca. frühes 1. Jh. n.Chr.
überlieferter Titel: Invectiva in M. Tullium Ciceronem
713 Wörter, 7 Kapitel
(fiktives) Datum der Rede: Herbst 54 v. Chr.
Genre: Declamatio im Stil einer Invektive
Forschungsfrage: Welche Unterschiede gibt es zwischen authentischen Invektiven und declamationes als Invektive?
Forschungsfokus Adressat: Wer ist der eigentliche Adressat einer Invektive? Der Diffamierte, die Senatoren, der Sprecher (als invertiertes Lob)?
Subfragen zu Genremerkmal, Diskursstruktur:
Welche Namen kommen wie oft vor? Zu welcher Kategorie von Entität gehören sie?
Wie verteilen sich die namentlichen Anreden über eine Rede?
Wie häufig wird der Diffamierte direkt (2.Sg.) oder die Senatoren (2.Pl.) angesprochen?
Wie häufig und wie wird über den Diffamierten indirekt (3.Sg.) gesprochen?
In welcher Beziehung stehen die Ich-Aussagen (1.Sg.) und die direkte Anrede?
Referenzkorpus 1: Ps.-Cicero, In Sallustium | Referenzkorpus 2: Cicero, In Pisonem
Methodisches Vorgehen#
Vorbemerkung: Führen Sie die Code-Abschnitte (= grau hinterlegt) schrittweise aus, indem Sie sie anklicken und dann im Menü auf das Play-Zeichen klicken. Ein Stern in den eckigen Klammern [*] am linken Zellenrand weist Sie darauf hin, dass die Ausführung des Codes noch andauert. Sobald aus dem Stern eine Zahl wird, ist die Zellenoperation fertig ausgeführt und Sie können mit dem nächsten Schritt fortfahren.

Für die Bedeutung der einzelnen Code-Blöcke lesen Sie bitte auch in den Code-Zellen die Kommentare, die mit # markiert sind.
Schritt 1: Text für die Analyse laden#
Es wird eine Textdatei (.txt), die vorher im Ordner “data” abgelegt wurde, in den Zwischenspeicher (Variable “text”) geladen. Im Rahmen des Forschungsvorhabens sind dies die Texte In Ciceronem (Ausgangstext), In Sallustium (Vergleichstext 1) und In Pisonem (Vergleichstext 2). Um zu überprüfen, ob es sich um die korrekte Datei handelt, lässt man sich das Ergebnis mit print(text) anzeigen.
Man kann die Ausgabe auch vermeiden, indem man die print-Funktion auskommentiert: #print(text)
with open('data/in_ciceronem.txt','r',encoding='utf-8') as file: # alternativ: in_sallustium.txt, in_pisonem.txt
text = file.read()
#print(text)
Schritt 2: Installation der Python-Bibliothek spaCy#
Für die NER-Analyse muss die Python-Bibliothek spaCy mit dem Paketmanager pip installiert. Dies kann u.U. etwas dauern.
!pip install -U spacy==3.8.4 numpy==1.26.4 numexpr==2.9.0
Collecting spacy==3.8.4
Downloading spacy-3.8.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (27 kB)
Collecting numpy==1.26.4
Downloading numpy-1.26.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (61 kB)
Collecting numexpr==2.9.0
Downloading numexpr-2.9.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (7.9 kB)
Collecting spacy-legacy<3.1.0,>=3.0.11 (from spacy==3.8.4)
Downloading spacy_legacy-3.0.12-py2.py3-none-any.whl.metadata (2.8 kB)
Collecting spacy-loggers<2.0.0,>=1.0.0 (from spacy==3.8.4)
Downloading spacy_loggers-1.0.5-py3-none-any.whl.metadata (23 kB)
Collecting murmurhash<1.1.0,>=0.28.0 (from spacy==3.8.4)
Downloading murmurhash-1.0.15-cp310-cp310-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl.metadata (2.3 kB)
Collecting cymem<2.1.0,>=2.0.2 (from spacy==3.8.4)
Downloading cymem-2.0.13-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl.metadata (9.7 kB)
Collecting preshed<3.1.0,>=3.0.2 (from spacy==3.8.4)
Downloading preshed-3.0.12-cp310-cp310-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl.metadata (2.5 kB)
Collecting thinc<8.4.0,>=8.3.4 (from spacy==3.8.4)
Downloading thinc-8.3.10-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl.metadata (15 kB)
Collecting wasabi<1.2.0,>=0.9.1 (from spacy==3.8.4)
Downloading wasabi-1.1.3-py3-none-any.whl.metadata (28 kB)
Collecting srsly<3.0.0,>=2.4.3 (from spacy==3.8.4)
Downloading srsly-2.5.2-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl.metadata (19 kB)
Collecting catalogue<2.1.0,>=2.0.6 (from spacy==3.8.4)
Downloading catalogue-2.0.10-py3-none-any.whl.metadata (14 kB)
Collecting weasel<0.5.0,>=0.1.0 (from spacy==3.8.4)
Downloading weasel-0.4.3-py3-none-any.whl.metadata (4.6 kB)
Collecting typer<1.0.0,>=0.3.0 (from spacy==3.8.4)
Downloading typer-0.24.1-py3-none-any.whl.metadata (16 kB)
Collecting tqdm<5.0.0,>=4.38.0 (from spacy==3.8.4)
Downloading tqdm-4.67.3-py3-none-any.whl.metadata (57 kB)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/site-packages (from spacy==3.8.4) (2.32.5)
Collecting pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4 (from spacy==3.8.4)
Downloading pydantic-2.12.5-py3-none-any.whl.metadata (90 kB)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/site-packages (from spacy==3.8.4) (3.1.6)
Requirement already satisfied: setuptools in /usr/local/lib/python3.10/site-packages (from spacy==3.8.4) (79.0.1)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/site-packages (from spacy==3.8.4) (26.0)
Collecting langcodes<4.0.0,>=3.2.0 (from spacy==3.8.4)
Downloading langcodes-3.5.1-py3-none-any.whl.metadata (30 kB)
Collecting annotated-types>=0.6.0 (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy==3.8.4)
Downloading annotated_types-0.7.0-py3-none-any.whl.metadata (15 kB)
Collecting pydantic-core==2.41.5 (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy==3.8.4)
Downloading pydantic_core-2.41.5-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (7.3 kB)
Requirement already satisfied: typing-extensions>=4.14.1 in /usr/local/lib/python3.10/site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy==3.8.4) (4.15.0)
Collecting typing-inspection>=0.4.2 (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy==3.8.4)
Downloading typing_inspection-0.4.2-py3-none-any.whl.metadata (2.6 kB)
Requirement already satisfied: charset_normalizer<4,>=2 in /usr/local/lib/python3.10/site-packages (from requests<3.0.0,>=2.13.0->spacy==3.8.4) (3.4.6)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/site-packages (from requests<3.0.0,>=2.13.0->spacy==3.8.4) (3.11)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/site-packages (from requests<3.0.0,>=2.13.0->spacy==3.8.4) (2.6.3)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/site-packages (from requests<3.0.0,>=2.13.0->spacy==3.8.4) (2026.2.25)
Collecting blis<1.4.0,>=1.3.0 (from thinc<8.4.0,>=8.3.4->spacy==3.8.4)
Downloading blis-1.3.3-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl.metadata (7.5 kB)
Collecting confection<1.0.0,>=0.0.1 (from thinc<8.4.0,>=8.3.4->spacy==3.8.4)
Downloading confection-0.1.5-py3-none-any.whl.metadata (19 kB)
Requirement already satisfied: click>=8.2.1 in /usr/local/lib/python3.10/site-packages (from typer<1.0.0,>=0.3.0->spacy==3.8.4) (8.3.1)
Collecting shellingham>=1.3.0 (from typer<1.0.0,>=0.3.0->spacy==3.8.4)
Downloading shellingham-1.5.4-py2.py3-none-any.whl.metadata (3.5 kB)
Collecting rich>=12.3.0 (from typer<1.0.0,>=0.3.0->spacy==3.8.4)
Downloading rich-14.3.3-py3-none-any.whl.metadata (18 kB)
Collecting annotated-doc>=0.0.2 (from typer<1.0.0,>=0.3.0->spacy==3.8.4)
Downloading annotated_doc-0.0.4-py3-none-any.whl.metadata (6.6 kB)
Collecting typer-slim<1.0.0,>=0.3.0 (from weasel<0.5.0,>=0.1.0->spacy==3.8.4)
Downloading typer_slim-0.24.0-py3-none-any.whl.metadata (4.2 kB)
Collecting cloudpathlib<1.0.0,>=0.7.0 (from weasel<0.5.0,>=0.1.0->spacy==3.8.4)
Downloading cloudpathlib-0.23.0-py3-none-any.whl.metadata (16 kB)
Collecting smart-open<8.0.0,>=5.2.1 (from weasel<0.5.0,>=0.1.0->spacy==3.8.4)
Downloading smart_open-7.5.1-py3-none-any.whl.metadata (24 kB)
Collecting wrapt (from smart-open<8.0.0,>=5.2.1->weasel<0.5.0,>=0.1.0->spacy==3.8.4)
Downloading wrapt-2.1.2-cp310-cp310-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl.metadata (7.4 kB)
Requirement already satisfied: markdown-it-py>=2.2.0 in /usr/local/lib/python3.10/site-packages (from rich>=12.3.0->typer<1.0.0,>=0.3.0->spacy==3.8.4) (3.0.0)
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/site-packages (from rich>=12.3.0->typer<1.0.0,>=0.3.0->spacy==3.8.4) (2.19.2)
Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.10/site-packages (from markdown-it-py>=2.2.0->rich>=12.3.0->typer<1.0.0,>=0.3.0->spacy==3.8.4) (0.1.2)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/site-packages (from jinja2->spacy==3.8.4) (3.0.3)
Downloading spacy-3.8.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (29.2 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/29.2 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━ 15.2/29.2 MB 77.9 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 29.1/29.2 MB 78.8 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 29.2/29.2 MB 71.0 MB/s 0:00:00
?25hDownloading numpy-1.26.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (18.2 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/18.2 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━ 16.5/18.2 MB 81.8 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 18.2/18.2 MB 67.4 MB/s 0:00:00
?25h
Downloading numexpr-2.9.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (375 kB)
Downloading catalogue-2.0.10-py3-none-any.whl (17 kB)
Downloading cymem-2.0.13-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (229 kB)
Downloading langcodes-3.5.1-py3-none-any.whl (183 kB)
Downloading murmurhash-1.0.15-cp310-cp310-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl (122 kB)
Downloading preshed-3.0.12-cp310-cp310-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl (780 kB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/780.3 kB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 780.3/780.3 kB 42.5 MB/s 0:00:00
?25hDownloading pydantic-2.12.5-py3-none-any.whl (463 kB)
Downloading pydantic_core-2.41.5-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.1 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/2.1 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 47.7 MB/s 0:00:00
?25hDownloading spacy_legacy-3.0.12-py2.py3-none-any.whl (29 kB)
Downloading spacy_loggers-1.0.5-py3-none-any.whl (22 kB)
Downloading srsly-2.5.2-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (1.1 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.1 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 32.7 MB/s 0:00:00
?25hDownloading thinc-8.3.10-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (3.9 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/3.9 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 42.4 MB/s 0:00:00
?25hDownloading blis-1.3.3-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (11.3 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/11.3 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 11.3/11.3 MB 60.5 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.3/11.3 MB 49.5 MB/s 0:00:00
?25h
Downloading confection-0.1.5-py3-none-any.whl (35 kB)
Downloading tqdm-4.67.3-py3-none-any.whl (78 kB)
Downloading typer-0.24.1-py3-none-any.whl (56 kB)
Downloading wasabi-1.1.3-py3-none-any.whl (27 kB)
Downloading weasel-0.4.3-py3-none-any.whl (50 kB)
Downloading cloudpathlib-0.23.0-py3-none-any.whl (62 kB)
Downloading smart_open-7.5.1-py3-none-any.whl (64 kB)
Downloading typer_slim-0.24.0-py3-none-any.whl (3.4 kB)
Downloading annotated_doc-0.0.4-py3-none-any.whl (5.3 kB)
Downloading annotated_types-0.7.0-py3-none-any.whl (13 kB)
Downloading rich-14.3.3-py3-none-any.whl (310 kB)
Downloading shellingham-1.5.4-py2.py3-none-any.whl (9.8 kB)
Downloading typing_inspection-0.4.2-py3-none-any.whl (14 kB)
Downloading wrapt-2.1.2-cp310-cp310-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl (113 kB)
Installing collected packages: wrapt, wasabi, typing-inspection, tqdm, spacy-loggers, spacy-legacy, shellingham, pydantic-core, numpy, murmurhash, langcodes, cymem, cloudpathlib, catalogue, annotated-types, annotated-doc, srsly, smart-open, rich, pydantic, preshed, numexpr, blis, typer, confection, typer-slim, thinc, weasel, spacy
?25l
━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3/29 [tqdm]
━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5/29 [spacy-legacy]
Attempting uninstall: numpy
━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5/29 [spacy-legacy]
Found existing installation: numpy 2.2.6
━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5/29 [spacy-legacy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
Uninstalling numpy-2.2.6:
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
Successfully uninstalled numpy-2.2.6
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8/29 [numpy]
━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━ 12/29 [cloudpathlib]
━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━ 16/29 [srsly]
━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━ 16/29 [srsly]
━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━ 18/29 [rich]
━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━ 18/29 [rich]
━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━ 18/29 [rich]
━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━ 19/29 [pydantic]
━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━ 19/29 [pydantic]
━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━ 20/29 [preshed]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━ 22/29 [blis]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━ 23/29 [typer]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━ 26/29 [thinc]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━ 26/29 [thinc]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━ 26/29 [thinc]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━ 27/29 [weasel]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━ 28/29 [spacy]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 29/29 [spacy]
?25h
Successfully installed annotated-doc-0.0.4 annotated-types-0.7.0 blis-1.3.3 catalogue-2.0.10 cloudpathlib-0.23.0 confection-0.1.5 cymem-2.0.13 langcodes-3.5.1 murmurhash-1.0.15 numexpr-2.9.0 numpy-1.26.4 preshed-3.0.12 pydantic-2.12.5 pydantic-core-2.41.5 rich-14.3.3 shellingham-1.5.4 smart-open-7.5.1 spacy-3.8.4 spacy-legacy-3.0.12 spacy-loggers-1.0.5 srsly-2.5.2 thinc-8.3.10 tqdm-4.67.3 typer-0.24.1 typer-slim-0.24.0 typing-inspection-0.4.2 wasabi-1.1.3 weasel-0.4.3 wrapt-2.1.2
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
Schritt 3: Installation des KI-Modells LatinCy#
Zur weiteren Vorbereitung der NER-Analyse brauchen Sie LatinCy, ein KI-Modell für Named Entity Recognition. Dies laden Sie mit dem nachfolgenden Code-Block herunter.
!pip install "la-core-web-lg @ https://huggingface.co/DaidalosTeam/LatinCy/resolve/main/la_core_web_lg-any-py3-none-any.whl"
ERROR: Invalid wheel filename (invalid version): 'la_core_web_lg-any-py3-none-any'
Schritt 4: Einbindung von spaCy und LatinCy in den Python-Code#
Nun binden Sie spaCy und LatinCy in den Python-Code ein, um die eigentliche Named Entity Recognition zu starten.
Der Algorithmus produziert anschließend eine Liste mit allen Entitäten (Eigennamen) im Textkorpus und gibt die Art der Entitäten an:
Person - PERSON,
Location - LOC,
Nationalities or religious or political groups - NORP
Der lateinspezifische Tagger kann keine weiteren Klassifizierungen vornehmen.
# Warnungsmeldungen der KI-Software sollen nicht angezeigt werden.
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import warnings
warnings.filterwarnings("ignore")
# Jetzt können wir die KI-Software einbinden.
import spacy
from spacy.tokens import Span
from spacy.matcher import Matcher
# das KI-Modell für NER wird initialisiert
nlp = spacy.load("la_core_web_lg")
# das KI-Modell für NER wird angewendet
doc = nlp(text)
# "patres conscripti" soll auch als Entität gelten, da sie nicht automatisch identifiziert wird
matcher = Matcher(nlp.vocab)
additional_person = "patres conscripti"
# das Suchmuster für "patres conscripti" in spaCy
pattern = [{"LOWER": x} for x in additional_person.split()]
matcher.add(additional_person, [pattern])
matched_spans = []
for match_id, start, end in matcher(doc):
span = doc[start:end]
# gefundene Muster erhalten die "PERSON"-Annotation
matched_spans.append(Span(doc, start, end, "PERSON"))
# Zusammenführung der neuen Annotationen zu "patres conscripti" mit den bereits existierenden
doc.set_ents(list(doc.ents) + matched_spans)
# alle Ergebnisse werden in einer Liste in der Reihenfolge des Vorkommens ausgegeben
for entity in doc.ents:
print(entity.text, entity.label_)
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[4], line 13
10 from spacy.matcher import Matcher
12 # das KI-Modell für NER wird initialisiert
---> 13 nlp = spacy.load("la_core_web_lg")
14 # das KI-Modell für NER wird angewendet
15 doc = nlp(text)
File /usr/local/lib/python3.10/site-packages/spacy/__init__.py:51, in load(name, vocab, disable, enable, exclude, config)
27 def load(
28 name: Union[str, Path],
29 *,
(...)
34 config: Union[Dict[str, Any], Config] = util.SimpleFrozenDict(),
35 ) -> Language:
36 """Load a spaCy model from an installed package or a local path.
37
38 name (str): Package name or model path.
(...)
49 RETURNS (Language): The loaded nlp object.
50 """
---> 51 return util.load_model(
52 name,
53 vocab=vocab,
54 disable=disable,
55 enable=enable,
56 exclude=exclude,
57 config=config,
58 )
File /usr/local/lib/python3.10/site-packages/spacy/util.py:472, in load_model(name, vocab, disable, enable, exclude, config)
470 if name in OLD_MODEL_SHORTCUTS:
471 raise IOError(Errors.E941.format(name=name, full=OLD_MODEL_SHORTCUTS[name])) # type: ignore[index]
--> 472 raise IOError(Errors.E050.format(name=name))
OSError: [E050] Can't find model 'la_core_web_lg'. It doesn't seem to be a Python package or a valid path to a data directory.
Schritt 5: Frequenzanalyse der vorkommenden Entitäten#
Es folgt ein erster Schritt der Aggregation der Daten: die Zusammenfassung der Werte pro Entität.
from collections import Counter
# die Zahl der vorkommenden Eigennamen pro NER-Klasse wird berechnet
ner_counter = Counter([entity.label_ for entity in doc.ents])
print(ner_counter.most_common())
[('PERSON', 26), ('LOC', 6), ('NORP', 5)]
Schritt 6: Frequenzanalyse der Entität Person und Häufigkeit des Adressaten#
Im nächsten Schritt wird für jede Entität der Kategorie PERSON erfasst, wie oft sie genannt wird. Die Liste ist absteigend sortiert, d.h. die häufigste Nennung steht ganz oben.
Darüber hinaus soll explizit ausgegeben werden, wie oft der im Titel der Rede ausgewiesene Adressat genannt wird: Cicero, Sallust, Piso. Gerade bei Cicero liegt die Besonderheit vor, dass er in der Invektive sowohl als Tullius als auch als Cicero angesprochen wird, deswegen müssen dafür die verschiedenen Muster definiert werden.
# Wie oft wird der Adressat namentlich angesprochen?
main_person = "Cicero" # alternativ: Sallustius, Piso
# Teil-Strings, an denen man die Erwähnung der Hauptperson erkennen kann, mögliche Varianten s. obige Namensliste
main_person_patterns = ["Cicero", "Tulli"]
addressee_mentions = [entity for entity in doc.ents if any(pattern for pattern in main_person_patterns if pattern in entity.text)]
name_counter = Counter([entity.text for entity in doc.ents if entity.label_ == "PERSON"])
main_person_counter = {}
person_counter = name_counter.copy()
for name in name_counter:
if any(pattern for pattern in main_person_patterns if pattern in name):
main_person_counter[name] = name_counter[name]
# verschiedene Erwähnungen des Adressaten werden zu einem einzigen Eintrag zusammengeführt
if name != main_person:
person_counter.update({main_person: name_counter[name]})
person_counter.pop(name)
main_person_frequency = sum(main_person_counter.values())
main_person_variants = list(main_person_counter.keys())
# Ausgabe der Häufigkeit der angesprochenen Person
print(f"Die in der Rede angesprochene Person {main_person} wird {main_person_frequency} Mal genannt, in folgenden Varianten: {main_person_variants}")
# Ausgabe der Liste, ganz oben steht der häufigst genannte Name, abwärts sortiert
print("Alle vorkommenden Namen: \n" + '\n'.join([str(x) for x in name_counter.most_common()]))
Die in der Rede angesprochene Person Cicero wird 6 Mal genannt, in folgenden Varianten: ['M. Tulli', 'M. Tullius', 'Cicero']
Alle vorkommenden Namen:
('Cicero', 3)
('M. Tulli', 2)
('patres conscripti', 2)
('M. Tullius', 1)
('Scipionis Africani', 1)
('M. Pisonem', 1)
('P. Crassi', 1)
('Terentia', 1)
('Plautiae', 1)
('Pompeianam', 1)
('Tusculanum', 1)
('Pompeianum', 1)
('M. Crassi', 1)
('Sullam', 1)
('Minerva', 1)
('Iuppiter', 1)
('Maximus', 1)
('Dyrrhachio', 1)
('Vatini', 1)
('Sestio', 1)
('Bibulum', 1)
('Caesarem', 1)
Schritt 7: Verteilung der Adressierung auf das Gesamtkorpus#
Der folgende Code-Block berechnet die Verteilung der direkten Ansprache des Adressaten auf den gesamten Text. Dazu werden folgende Fragen durch Berechnung beantwortet:
Mit welchem Wortlaut wird der Adressat angesprochen?
An welcher Stelle im Text, d.h. beim wievielten Wort, wird der Adressat genannt?
Wie viele Wörter folgen bis zu seiner nächsten Nennung?
Wie viel macht dieser Abstand prozentual vom Gesamttext aus?
# Anlegen der Tabelle: Ausgabe der Kopfzeile und eines Trennstrichs
print('| Wortlaut | Wortposition im Text | Abstand zur nächsten Nennung | Abstand als Prozentsatz vom Gesamtkorpus |')
print('---------------------------------------------------------------------------------------------------------------')
# eigentliche Berechnung
for mention_index in range(len(addressee_mentions)):
current_mention = addressee_mentions[mention_index]
if len(addressee_mentions) > mention_index + 1:
next_mention = addressee_mentions[mention_index + 1]
distance = next_mention.start - current_mention.start
else:
distance = len(doc) - current_mention.start
values = [current_mention.text, current_mention.start, distance, int(round(distance / len(doc), 2) * 100)]
# Ausgabe der Werte in der Tabelle, die Werte in den geschweiften Klammern legen die Spaltenbreite fest
print('| {:10} | {:>20} | {:>28} | {:>39}% |'.format(*values))
| Wortlaut | Wortposition im Text | Abstand zur nächsten Nennung | Abstand als Prozentsatz vom Gesamtkorpus |
---------------------------------------------------------------------------------------------------------------
| M. Tulli | 8 | 97 | 11% |
| M. Tullius | 105 | 41 | 5% |
| M. Tulli | 146 | 134 | 15% |
| Cicero | 280 | 294 | 34% |
| Cicero | 574 | 81 | 9% |
| Cicero | 655 | 219 | 25% |
Schritt 8: Häufigkeitsverteilung von Entitäten im Gesamtkorpus#
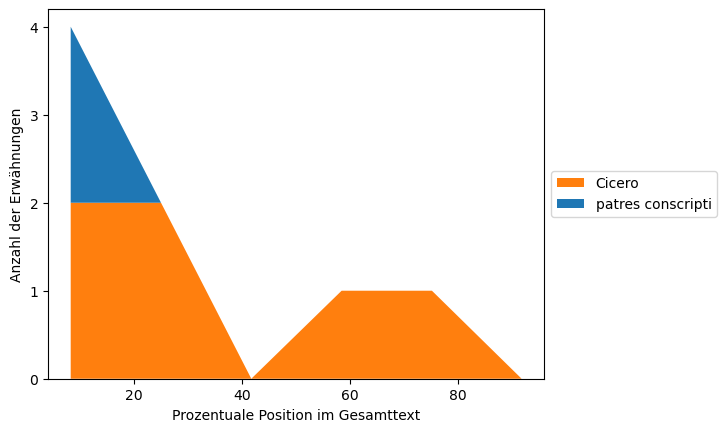
Für die Frage nach dem Adressaten der Invektive werden die beiden naheliegenden Adressaten (“Namensgeber der Rede”, “patres conscripti”) verglichen: Wie oft wird die jeweilige PERSON über den Verlauf des Gesamtwerks hinweg genannt?
import matplotlib.pyplot as plt
def chunks(lst, n):
"""Yield successive n-sized chunks from a list."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
# Der Text soll in mehrere Stücke aufgeteilt werden. Dazu müssen wir wissen, wie viele Wörter er hat.
text_length = len(doc)
# Wie oft wurde die Hauptperson erwähnt?
main_person_mention_count = person_counter[main_person]
# Die Größe der Textteilstücke richtet sich nach der Zahl der Erwähnungen der Hauptperson.
chunk_size = (text_length // main_person_mention_count) + 1
doc_chunks = list(chunks(doc, chunk_size))
# Die x-Achse der folgenden Visualisierungen gibt die prozentuale Position im Text an.
x = [((chunk.start + len(chunk) // 2) / len(doc)) * 100 for chunk in doc_chunks]
Schritt 9: Visualisierung der Häufigkeitsverteilung bestimmter Entitäten#
Die Visualisierung erfolgt als gestapeltes Flächendiagramm (Stacked Area Plot/Chart/Graph).
A stacked area chart displays the evolution of a numeric variable for several groups of a dataset. Each group is displayed on top of each other, making it easy to read the evolution of the total, but hard to read each group value accurately.
Quelle: The Python Graph Gallery
def plot_person_mentions():
# Für die Analyse schauen wir uns nur den Adressaten und die Senatoren an.
all_classes = [main_person, additional_person]
ys = [[] for i in range(len(all_classes))]
# Wir schauen jetzt die Textteilstücke nacheinander an.
for doc_chunk in doc_chunks:
# Welche Personen kommen in diesem Textteilstück vor?
relevant_entities = [entity for entity in doc_chunk.ents if entity.label_ == "PERSON"]
for class_index, target_class in enumerate(all_classes):
# Woran erkenne ich die Erwähnungen der wichtigsten Personen im Text?
patterns = main_person_patterns if target_class == main_person else [target_class]
# Wie oft kommen die wichtigsten Personen in diesem Textteilstück vor?
count = len([1 for entity in relevant_entities if any(pattern for pattern in patterns if pattern in entity.text)])
ys[class_index].append(count)
# Angleichung der Farbgebung an den nachfolgenden Plot
plt.stackplot(x, *ys, labels=all_classes, colors=["tab:orange", "tab:blue"])
# Beschriftung der x-Achse
plt.xlabel("Prozentuale Position im Gesamttext")
# Beschriftung der y-Achse
plt.ylabel("Anzahl der Erwähnungen")
highest_y_value = max([sum([y[i] for y in ys]) for i in range(len(ys[0]))])
# Nur ganzzahlige Werte sind für die Einteilung der y-Achse (Erwähnunugsfrequenz) geeignet.
plt.yticks(range(highest_y_value + 1), [str(x) for x in range(highest_y_value + 1)])
# Wo soll in der Visualisierung die Legende zu sehen sein?
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
# Export des Diagramms in eine Grafikdatei (.png)
plt.savefig("personen_erwaehnungen_in_ciceronem.png", bbox_inches='tight')
plt.show()
Schritt 10: Häufigkeitsverteilung der Verbformen#
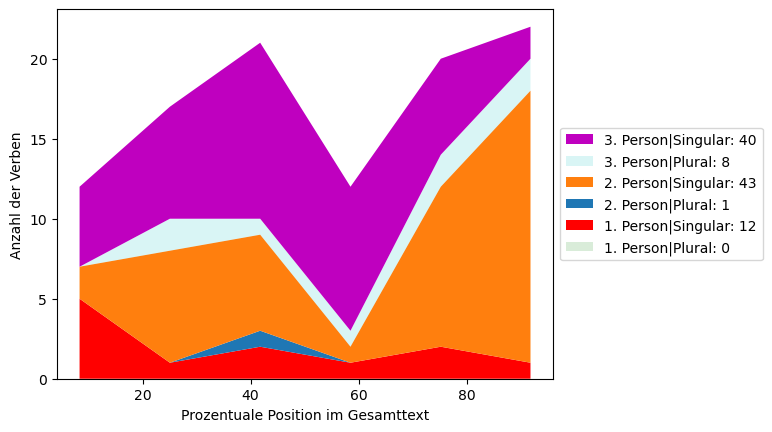
Ergänzend zur namentlichen Nennung werden Adressaten auch implizit über die Verbform angesprochen. Deswegen werden nun für alle Verben die Person und der Numerus erhoben: Wie oft kommen finite Verben in der 2. oder 3. Person vor?
# Zuordnung der Annotationen im Text zu menschenlesbaren Werten
person_label_to_feature_value = {"1. Person": "1", "2. Person": "2", "3. Person": "3"}
number_label_to_feature_value = {"Plural": "Plur", "Singular": "Sing"}
# jeder Numerus kann mit jedem Personenwert kombiniert werden
all_classes = ["|".join([x, y]) for x in person_label_to_feature_value for y in number_label_to_feature_value]
ys = [[] for i in range(len(all_classes))]
label_to_frequency = {}
label_counter = Counter()
# Wir schauen uns nacheinander alle Textteilstücke an.
for doc_chunk in doc_chunks:
labels = []
# Wir schauen uns nacheinander alle Wörter in diesem Textteilstück an.
for token in doc_chunk:
person_value = token.morph.get("Person")
# Wir betrachten nur die Verben, keine Pronomina.
if len(person_value) and token.tag_ == "verb":
# Welcher Numerus wurde annotiert?
number_value = token.morph.get("Number")
# Ignoriere Wörter, für die kein Numerus annotiert wurde, obwohl eine Person annotiert wurde.
if not len(number_value):
continue
labels.append("|".join([person_value[0], number_value[0]]))
for class_index, target_class in enumerate(all_classes):
class_labels = target_class.split('|')
# Aus den Annotationen für Person und Numerus ergibt sich das finale Label für die Visualisierung.
class_pattern = "|".join([person_label_to_feature_value[class_labels[0]], number_label_to_feature_value[class_labels[1]]])
count = labels.count(class_pattern)
ys[class_index].append(count)
label_counter.update({target_class: count})
# Ausgabe der Liste, ganz oben steht die häufigste Kombination aus grammatischer Person und Numerus, abwärts sortiert
print("Alle vorkommenden Kombinationen: \n" + '\n'.join([str(x) for x in label_counter.most_common()]))
Alle vorkommenden Kombinationen:
('2. Person|Singular', 43)
('3. Person|Singular', 40)
('1. Person|Singular', 12)
('3. Person|Plural', 8)
('2. Person|Plural', 1)
('1. Person|Plural', 0)
Schritt 11: Visualisierung der Verbfrequenzen im Gesamtkorpus#
Die Visualisierung erfolgt als gestapeltes Flächendiagramm (Stacked Area Plot/Chart/Graph). Die Farben für die 2. Person Singular und die 2. Person Plural werden für einen besseren Vergleich den Farben aus dem ersten Plot angeglichen:
Person Singular = Cicero bzw. “Namensgeber der Rede” = orange
Person Plural = patres conscripti = blau
from matplotlib.colors import to_rgba
def plot_morphology():
# Angleichung der Farbgebung an den vorangehenden Plot
colors = ["g", "r", "tab:blue", "tab:orange", "c", "m"]
# 1. Pl. und 3. Pl. sind unwichtig und bekommen daher blassere Farben
for i in [0, 4]:
colors[i] = to_rgba(colors[i], alpha=0.15)
labels_with_frequencies = [f"{label}: {label_counter[label]}" for label in all_classes]
plt.stackplot(x, *ys, labels=labels_with_frequencies, colors=colors)
# Beschriftung der x-Achse
plt.xlabel("Prozentuale Position im Gesamttext")
# Beschriftung der y-Achse
plt.ylabel("Anzahl der Verben")
handles = list(reversed(plt.legend().legend_handles))
# Wo soll in der Visualisierung die Legende zu sehen sein?
plt.legend(handles, list(reversed(labels_with_frequencies)), loc='center left', bbox_to_anchor=(1, 0.5))
# Export des Diagramms in eine Grafikdatei
plt.savefig("numerus_und_person_in_ciceronem.png", bbox_inches='tight')
plt.show()
Schritt 12: Ausgabe der beiden Graphen#
Aufruf der beiden zuvor definierten Funktionen zur Visualisierung. Dadurch werden beide zusammen angezeigt.
plot_person_mentions()
plot_morphology()
Literatur#
Zur allgemeinen Einführung#
GeeKsforGeeks: https://www.geeksforgeeks.org/named-entity-recognition/
forText - Literatur digital erforschen: https://fortext.net/routinen/methoden/named-entity-recognition-ner
Literatur für den (fachlichen) Einstieg#
Berti, Monica. 2023. “Named Entity Recognition for a Text-Based Catalog of Ancient Greek Authors and Works.” In Digital Humanities 2023: Book of Abstracts, edited by Anne Baillot, Toma Tasovac, Walter Scholger, and Georg Vogeler. https://www.academia.edu/download/107756648/BERTI_Monica_Named_Entity_Recognition_for_a_Text_Based_Catal.pdf.
Broux, Yanne, and Mark Depauw. 2014. “Developing Onomastic Gazetteers and Prosopographies for the Ancient World through Named Entity Recognition and Graph Visualization: Some Examples from Trismegistos People.” In Social Informatics. SocInfo 2014, edited by Luca Maria Aiello and Daniel McFarland, 304–13. Springer. https://lirias.kuleuven.be/retrieve/285982.
Milanova, Ivona, Jurij Silc, Miha Serucnik, Tome Eftimov, and Hristijan Gjoreski. 2019. “LOCALE: A Rule-Based Location Named-Entity Recognition Method for Latin Text.” In , 13–20. https://ceur-ws.org/Vol-2461/paper_3.pdf.
Weiterführende Literatur#
Aguilar, Sergio Torres. 2022. “Multilingual Named Entity Recognition for Medieval Charters Using Stacked Embeddings and Bert-Based Models.” In Proceedings of the Second Workshop on Language Technologies for Historical and Ancient Languages, 119–28. https://aclanthology.org/2022.lt4hala-1.17.pdf.
Aguilar, Sergio Torres, Xavier Tannier, and Pierre Chastang. 2016. “Named Entity Recognition Applied on a Data Base of Medieval Latin Charters. The Case of Chartae Burgundiae.” In . https://hal.science/hal-02407159/document.
Boroş, Emanuela, Verónica Romero, Martin Maarand, Kateřina Zenklová, Jitka Křečková, Enrique Vidal, Dominique Stutzmann, and Christopher Kermorvant. 2020. “A Comparison of Sequential and Combined Approaches for Named Entity Recognition in a Corpus of Handwritten Medieval Charters.” In , 79–84. IEEE. https://storage.teklia.com/teklia-public-website/documents/ICFHR2020_NER_Comparison_final_updated_Q0Qt4Te.pdf.
Carstensen, Kai-Uwe. 2010. “Anwendungen.” In Computerlinguistik und Sprachtechnologie: Eine Einführung, edited by Kai-Uwe Carstensen, Christian Ebert, Cornelia Ebert, Susanne J. Jekat, Ralf Klabunde, and Hagen Langer, 553–658. Heidelberg: Spektrum Akademischer Verlag. https://doi.org/10.1007/978-3-8274-2224-8_5.
Chastang, Pierre, Sergio Octavio Torres Aguilar, and Xavier Tannier. 2021. “A Named Entity Recognition Model for Medieval Latin Charters.” Digital Humanities Quarterly 15 (4).
Collar, Anna. 2013. Religious Networks in the Roman Empire: The Spread of New Ideas. Cambridge University Press.
Dressler, Alex. 2016. “Nominal Intelligence: Conspiracy, Prosopography, and the Secret of Horace.” Wordplay and Powerplay in Latin Poetry 36:37.
Ehrmann, Maud, Ahmed Hamdi, Elvys Linhares Pontes, Matteo Romanello, and Antoine Doucet. 2021. “Named Entity Recognition and Classification in Historical Documents: A Survey.” ACM Computing Surveys. https://dl.acm.org/doi/pdf/10.1145/3604931.
González-Gallardo, Carlos-Emiliano, Hanh Thi Hong Tran, Ahmed Hamdi, and Antoine Doucet. 2024. “Leveraging Open Large Language Models for Historical Named Entity Recognition.” In The 28th International Conference on Theory and Practice of Digital Libraries, 379–95. Springer. https://univ-rochelle.hal.science/hal-04662000/document.
Horster, Marietta. 2007. “The Prosopographia Imperii Romani (PIR) and New Trends and Projects in Roman Prosopography.” Prosopography. Approaches and Applications, 231–40.
Mack, William Joseph Behm Garner. 2015. Proxeny and Polis: Institutional Networks in the Ancient Greek World. Oxford University Press.
Malkin, Irad. 2011. A Small Greek World: Networks in the Ancient Mediterranean. Oxford University Press.
Palladino, Chiara, and Tariq Yousef. 2024. “Development of Robust NER Models and Named Entity Tagsets for Ancient Greek.” In Proceedings of the Third Workshop on Language Technologies for Historical and Ancient Languages, 89–97. European Language Resources Association (ELRA). https://findresearcher.sdu.dk/ws/portalfiles/portal/260634454/2024.lt4hala-1.11.pdf.
Roueché, Charlotte, Averil Cameron, and Janet L Nelson. 2023. “Prosopography Meets the Digital: PBW and PASE.” On Making in the Digital Humanities. The Scholarship of Digital Humanities Development in Honour of John Bradley, 51–65.
Taylor, Claire. 2011. “Women’s Social Networks and Female Friendship in the Ancient Greek City.” Gender & History 23 (3): 703–20.
Yousef, Tariq, Chiara Palladino, Gerhard Heyer, and Stefan Jänicke. 2023. “Named Entity Annotation Projection Applied to Classical Languages.” In Proceedings of the 7th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, 175–82. https://aclanthology.org/2023.latechclfl-1.19.pdf.
Yousef, Tariq, Chiara Palladino, and Stefan Jänicke. 2023. “Transformer-Based Named Entity Recognition for Ancient Greek.” In Digital Humanities 2023: Book of Abstracts, 420–22. Graz: Zenodo. https://doi.org/10.5281/zenodo.8107629.