… von Bittbriefen#
Automatisierte Kategorisierung mittellateinischer Bittbriefe an den Papst#
Wovon handeln Bittbriefe an den Papst im Spätmittelalter? Es gibt eine große Bandbreite an Anlässen, die zur Abfassung einer solchen Bittschrift führen können – seien es weltliche Gründe, sei es die Sorge um das Seelenheil.
In diesem Forschungstandem wird ein Sprachmodell trainiert, um Tausende solcher mittellateinischen Bittbriefe aus dem ehemaligen Deutschen Reich automatisch kirchenrechtlichen Vergehenskategorien wie Fastenbruch oder Mord zuzuordnen.
Wie kommt ein Bittbrief im Mittelalter zustande?
Üblicherweise begehen die Gläubigen ein Vergehen, wenden sich daraufhin aufgrund ihrer Gewissensnöte an den Papst und bitten in einem Gnadengesuch etwa um eine Sondergenehmigung. Dabei wendet sich eine Person, die einen Bittbrief (Supplik, Gnadengesuch) einreicht (Petent, exponens), in der Regel an einen Prokurator als vermittelnde Instanz, damit sprachliche und strukturelle Formalia eingehalten werden (stilus curiae).

Abbildung 1: Beispiel für einen Bittbrief, 1460; Salonen & Schmugge (2009). A Sip from the „Well of Grace“, S. 166.

Abbildung 2: Transkript und Übersetzung des Bittbriefs von Salonen & Schmugge (2009). A Sip from the „Well of Grace“, S. 116f.
Was erhoffen sich die Gläubigen von einem Bittbrief?
Ein Bittbrief ist ein Medium zur Kontaktaufnahme mit dem Papst. Auch wenn wegen steigender Fallzahlen nicht auf eine Antwort vom Papst selbst zu hoffen ist, verfügt seine institutionelle Vertretung über alle nötigen Vollmachten (plenitudo potestatis), um im Einzelfall zu entscheiden: So gehört es zu den Aufgaben der unmittelbar dem Papst unterstellten Apostolischen Pönitentiarie (Sacra Poenitentiaria Apostolica) als höchstem päpstlichen Gnadenamt, mit dem Kardinalgroßpönitentiar an der Spitze, Gnadenerweise, Absolutionen und Dispense zu gewähren.
Zu beachten ist allerdings, dass in den Registern der Pönitentiarie nur die positiv beschiedenen Bittbriefe und nicht die Antwortschreiben enthalten sind. (Registriert wurde übrigens nur gegen Aufpreis.)
Relevanz für die Forschung:
Über 40 000 Bittbriefe aus der Zeit von 1431-1523 führt das untersuchte Register. Die meisten davon sind thematisch erfasst und einem der vier inhaltlichen Schwerpunkte zugeordnet: Ehesachen (De matrimonialibus), Geburtsmakel (De defectu natalium et de uberiori), klerikale Karrieren (De promotis et promovendis) und Beichtprivilegien (De confessionalibus).
Doch 9070 Bittbriefe werden unspezifisch unter „Diverses“ geführt (De diversis formis et de declaratoriis). Obwohl diese Texte bereits digital vorliegen und fraglos von hohem kulturgeschichtlichem Wert sind, bekommen sie in der Forschung noch wenig Aufmerksamkeit. Die Gründe sind unklar. Liegt es an der Unübersichtlichkeit?
Mithilfe von Textklassifikation, einer Methode des Natural Language Processing (NLP), versucht ein Daidalos-Forschungstandem die behandelten Themen der Bittbriefe zu erfassen. Wenn es erfolgreich ist, kann es die inhaltliche Variation der Bittbriefe beleuchten und womöglich auch das Interesse an weiterer Erforschung dieser noch kaum bekannten Bittbriefe wecken.
Forschungsfrage:
Lassen sich die Registereinträge, die in den Registern der Pönitentiarie unter der Überschrift De diversis formis et de declaratoriis verzeichnet sind, mithilfe von NLP-Tools automatisiert in vorher festgelegte thematische Kategorien einordnen?
Anhand eines umfangreichen historischen Registerkorpus, dem Repertorium Poenitentiariae Germanicum (RPG) untersucht ein Doktorand der Latinistik diese Frage in einem Forschungstandem mit dem NLP-Experten Konstantin Schulz aus dem Daidalos-Team.
Informationen zum Textkorpus:#
Sprache: Mittellatein
Zeitraum: 1431-1523
Textarten: Bittbriefe bzw. Registereinträge (gekürzte Kopien der Bittbriefe)
Autoren: Petenten bzw. (kirchliche) Schreiber der Bittbriefe
Weitere Schlüsselwörter: Spätmittelalter, Apostolische Pönitentiarie, Gnade, Absolution, Supplik
Aufbau des Textkorpus:#
Untersuchungskorpus:
9070 Bittbriefe (RPG, Diverses)
Vergleichskorpus:
Trainingsdaten: ca. 300 manuell annotierte und digital verfügbare Bittbriefe (RPG, Diverses) aus Erzdiözese Magdeburg
Methodenauswahl, Arbeitsschritte und Hindernisse:#
Die Forschungsfrage bestimmt die Methode: Da es sich bei der Aufgabe für die maschinelle Textverarbeitung um automatisierte Kategorisierung handelt, fällt die Wahl auf die NLP-Methode Textklassifikation.
Die Idee hinter Textklassifikation ist es, durch sprachliche Muster zu erkennen, worum es in einem Brief geht.
Um eine KI entsprechend zu trainieren, braucht es zuverlässige Trainingsdaten.
Bereitstellung von Trainingsdaten#
Im ersten Arbeitsschritt stellt der Latinist als Grundlage für das Training einen Datensatz zur Verfügung: eine händische Zuordnung der ca. 300 Bittbriefe zu einer von 17 Kategorien in Excel-Dateien.
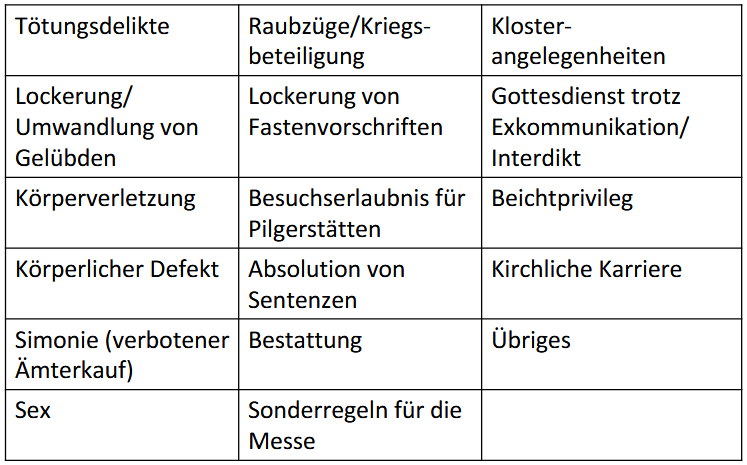
Abbildung 3: 17 Kategorien, Modifikation nach Schmugge/Hersperger/Wiggenhauser (1996).
Training und Spezialisierung einer lateinischen KI#
Wie trainiert man eine KI für mittellateinische Bittbriefe?
Damit liegen die Trainingsdaten nun vor und es kann losgehen: Konstantin sucht ein geeignetes KI-Modell (dieses Sprachmodell) als Basis aus. Man kann es sich ähnlich wie ChatGPT vorstellen, aber in diesem Fall wurde die KI auf dem gesamten lateinischen Internet (ca. 600 Megabytes lateinischer Rohtext) trainiert.
(Anmerkung: Vom verlinkten mehrsprachigen Datensatz wurde nur der lateinische Teil für das Training des lateinischen LLMs benutzt.)
Im nächsten Schritt muss sich die Latein-KI auf Textklassifikation spezialisieren: Sie bekommt Text als Input und soll eine Kategorie bzw. ein Delikt-Label als Output geben.
Die Zuordnung des Delikt-Labels erfolgt wahrscheinlichkeitsbasiert. Das läuft so ab: Für jede einzelne der 17 Kategorien berechnet die KI eine Wahrscheinlichkeit. Das Delikt-Label mit der höchsten Wahrscheinlichkeit „gewinnt“ sozusagen. Dabei wird nur ein einziges Label als Ergebnis ausgegeben.
Evaluation#
Das Ergebnis auf den Trainingsdaten ist vielversprechend: 94,6 % korrekte Zuordnungen.
Allerdings liegt bei den Testdaten die Treffsicherheit nur noch bei 50 %.
Was bedeutet das? Konstantin sieht hierin einen Hinweis auf Overfitting und definiert es so: „Overfitting ist, wenn das Modell einfach die Texte aus den Trainingsdaten auswendig lernt, anstatt allgemeinere Rückschlüsse zu ziehen, die sich auch auf andere Texte übertragen ließen. […]. Overfitting erkennt man oft daran, dass die Leistung beim Training (92%) stark von der Leistung bei neuen Texten (50%) abweicht.“
Wie kommt es aber dazu?
Problemsuche#
Es stellen sich Fragen in Bezug auf die Textlänge, Mehrfachzuordnungen und die Auflösung von Abkürzungen. Denn all diese Faktoren haben einen maßgeblichen Einfluss auf die Performance der KI.
Weitere Anpassungen#
Aus diesen Gründen sind weitere Anpassungen notwendig.
Eine mögliche Lösung kann sein, die Anzahl der Kategorien auf weniger als 17 zu reduzieren. Wenn nämlich weniger Delikt-Labels zur Auswahl stehen, wird das Training für den Algorithmus leichter.
So können ähnliche Kategorien in einer übergeordneten Kategorie zusammengefasst werden:
„Gewaltdelikte“: Tötungsdelikte, Körperverletzung, Raubzüge/Kriegsbeteiligung
„Sondererlaubnis“: Lockerung von Fastenvorschriften, Besuchserlaubnis von Pilgerstätten, Lockerung/Umwandlung von Gelübden, Beichtprivilegien, Sonderregel Messe
Weiterhin ist es auch nötig, das Trainingsmaterial anzupassen: Häufig ist die Worttrennung im Digitalisat mangelhaft und Abkürzungen im Text müssen aufgelöst werden. Dafür ist Domänenwissen nötig. Das heißt, der Latinist ist mit seiner Expertise gefragt, damit das Forschungstandem in eine gute Richtung steuern kann.